강화학습 기초
- 강화학습은 순차적으로 행동을 결정해야 하는 문제를 푸는 것이다.
- 이를 수학적으로 표현한 것이 MDP이다.
- MDP는 상태, 행동, 보상함수, 상태 변환 확률(state transition probability), 감가율(Discount Factor)로 구성
- 상태 변환 확률 : 환경의 변화가 상태에 미치는 영향을 확률로 표현
- 영향을 미치지 않는 경우 상태 변환 확률은 1
상태
- 상태는 '자신의 상황에 대한 관찰'을 말한다.
- 로봇과 같은 실제 세상에서의 에이전트에게 상태는 센서 값이 된다.
행동
- 보통 에이전트가 할 수 있는 행동은 모든 상태에서 같다.
보상함수
- 보상은 에이전트가 학습할 수 있는 유일한 정보로서 환경이 에이전트에게 주는 정보이다.
- 보상함수는 s 상태와 a 행동일 때 받을 보상에 대한 기댓값 E이다.

감가율
- 에이전트가 항상 현재에 판단을 내리기 때문에 현재에 가까운 보상일수록 더 큰 가치를 가진다.
- 같은 보상이면 나중에 받을수록 가치가 줄어든다. 이를 감가율(Discount Factor)이라고 한다.
- 감가율은 [0, 1]이다.

정책
- 정책은 모든 상태에서 에이전트가 할 행동이다.
- 정책은 상태가 입력으로 들어오면 행동을 출력으로 내보내는 일종의 함수이다.
- 시간 t에 S_t = s 에 에이전트가 있을 때 가능한 행동 중 A_t = a 를 할 확률을 나타낸다.

- 에이전트는 현재 상태에서 앞으로 받을 보상들을 고려해서 행동을 결정한다.
- 환경은 에이전트에게 실제 보상과 다음 상태를 알려누다.
- 과정을 반복하며 에이전트는 앞으로 받을 것이라 예상했던 보상에 대해 틀렸다는 것을 알게 된다. 이 때 받을 것이라 예상하는 보상을 가치함수(value Function)이라고 한다.

가치함수
-
에이전트가 어떤 행동을 하는 것이 좋은지를 알 수 있는 방법은 현재 상태에서 앞으로 받을 보상들을 고려해서 선택하는 것이다.
-
아직 받지 않은 보상들을 고려하는 것을 가치함수라고 한다.
-
보상을 구할 때 감가를 고려하지 않으면 문제가 생긴다.
- 시간이 무한대라고 가정하면 보상이 0.1일 때과 1일때 둘 다 합이 무한대이다. -> 수치적으로 구분 불가
-
에이전트는 앞으로 얼마의 보상을 받을 것을 예측한다.
가치함수 : 지금 상태에서 미래에 받을 것이라 기대하는 보상의 합

반환 값
- 반환 값이란 에이전트가 실제로 환경을 탐험하며 받은 보상의 합이다.
- 만약 에피소드를 t=1부터 5까지 진행했다면, 다음과 같이 5개의 반환값이 생성된다.

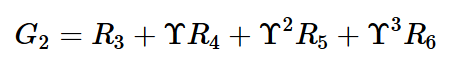



- 각 타임 스텝마다 받는 보상이 확률적이고 반환 값이 그 보상들의 합이므로 반환 값은 확률 변수이다.
큐함수
-
어떤 상태에서 각 행동에 대해 따로 가치함수를 만들어서 그 정보를 얻어 올 수 있다면 에이전트는 굳이 다음 상태의 가치함수를 따져보지 않아도 어떤 행동을 해야 할지 선택할 수 있다.
-
어떤 상태에서 어떤 행동이 얼마나 좋은지 알려주는 함수를 행동 가치함수, 다른 말로 큐 함수(Q function)라고 한다.
큐 함수 : 지금 상태에서 이 행동을 선택했을 때 미래에 받을 것이라 기대하는 보상의 합
행동 -> 큐함수 -> 앞으로 받을 보상의 합(기댓값)
-
큐함수는 상태, 행동이라는 두 가지 변수를 가진다.
-
모든 행동에 대해 큐함수와 정책을 곱한 값을 더하면 가치함수가 된다.

가치함수 = (모든 행동에 대한) 정책 * 큐함수
앞으로 받을 보상의 합 = (모든 행동에 대한) 어떤 상태 s에서 행동 a를 할 확률 값 x 어떤 상태 s 에서 행동 a를 했을 때 받을 것이라 기대되는 보상의 합
- 큐함수를 벨만 기대 방정식 형태로 바꾸면 아래와 같다.

큐 함수 : 지금 상태 s에서 이 행동 a를 선택했을 때 미래에 받을 것이라 기대(기댓값)하는 보상의 합
가치함수의 수식과 비교하면 행동 a 조건이 추가되었다.
벨만 기대 방정식
- 현재 가치함수와 다음 가치함수 사이의 관계
- 가치함수는 현재 에이전트의 정책에 영향을 받는데, 정책(pi)을 반영해 가치함수를 바꾸면 벨만 기대 방정식이 된다.




앞의 가치함수와 다른 점은 정책이 반영되어 있다는 점이다.
정책이 반영되었다는 것은 모든 상태에서 어떤 행동을 할지 정해져 있다는 것이므로, 행동에 관한 조건이 수식에서 빠진다.

벨만 최적 방정식
- 최적의 가치함수는 수 많은 정책 중에서 가장 높은 보상을 주는 가치함수이다.
- 최적의 가치함수 = 최적의 큐함수 중 max 값
- 최적 정책 하에서 현재 상태의 큐함수 = 선택 가능한 행동 중 가장 높은 큐함수 * 감가율 + 보상



현재의 큐함수를 다음 타임스탬프의 큐함수로 표현할 수 있다.
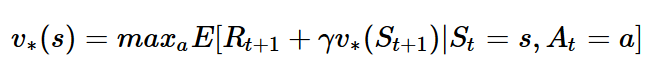

*** 수식상 오류가 몇 군데 있습니다. Upsion -> gamma
'프로그래머 > 강화학습' 카테고리의 다른 글
| [강화학습] 1. 강화학습 개요 (0) | 2020.05.22 |
|---|
